提取文本字符串中下划线后紧跟的单词
要从字符串中捕获下划线后的单词(不包括下划线本身),可以使用以下正则表达式:
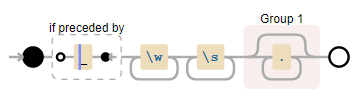
正则表达式示例
_\w+\s([\w\s]+)
该正则表达式的运作方式如下:
_\w+\s 匹配下划线单词及其后面的空格。([\w\s]+) 然后捕获一系列包含单词字符和空格的序列。
在实际应用中,可以在Python中这样实现这个正则表达式:
import re
testString = '21 High Street _Earth Mighty Motor Mechanic'
pattern = r'_\w+\s([\w\s]+)'
match = re.search(pattern, testString)
if match:
words_after = match.group(1).split()
count = len(words_after)
print(f"下划线单词之后的单词数量: {count}")
else:
print("未找到下划线单词或其后无任何单词。")
---
### 提取文本字符串中以下划线开始的单词序列
如果你想包含下划线单词在计数内,可以稍微修改上述正则表达式:
[正则表达式示例](https://regex101.com/r/dbGoqr/1)
```python
(_\w+\s[\w\s]+)
这个版本的工作原理如下:
(_\w+\s[\w\s]+) 捕获下划线单词及其后面的所有单词。其中,_\w+ 匹配下划线单词,\s[\w\s]+ 则匹配其后的空格及单词。
对应的Python实现为:
import re
testString = '21 High Street _Earth Mighty Motor Mechanic'
pattern = r'(_\w+\s[\w\s]+)'
match = re.search(pattern, testString)
if match:
words = match.group(1).split()
count = len(words)
print(f"包括下划线单词在内的总单词数: {count}")
else:
print("未找到下划线单词或其后无任何单词。")
注意:在这两个正则表达式之间进行选择取决于你是否希望将下划线单词计入词数统计。